

What if a hackathon could help to improve a working model?
During our hackathon of March, we gave the contenders a dataset with historic data from Amber, an all-electrical car sharing company. We use their cars with a lot of pleasure - in fact during our pilot period we saved 260kg of CO2 emission by driving over 2,000 electric kilometers.
We also partner with Amber at data science level: we have built and maintain a prediction model to define how many cars are needed per hub.
For the hackathon we already executed the cleaning and some feature engineering. We even gave away settings for a baseline model to start with - and some ideas for potential improvements. This hackathon was an opportunity to be creative, and the teams did not let us down.
The challenge was to predict the number of checkouts for electrical cars per hub per daypart, for the two weeks that followed the historic dataset. Furthermore, some advice needed to be formulated on how to further improve the model. The quality of the scoring was measured using RMSE and the creativity of the approach and the quality of the advice was measured using our famous applause meter.

Teams are preparing for the challenge
In the first hour of the hackathon, most teams chose to split up, part of the team exploring the data and the other part trying to find external data sources. There were some splendid ideas, like including traffic information and demographic information of the hub region. Tragically though, in the time that followed, most of the ideas seemed infeasible.
A validation RMSE of 0.24, too good to be true?
The models chosen included a simple regression model based on only one variable, a Random Forest and of course… XGBoost models. The baseline score was around 1.2, and with one hour to go, one of the teams claimed to have reached an RMSE of only 0.24 on their validation data. Usually, when something looks too good to be true, it is too good to be true. And so it was in this case. Their test RMSE was 750% higher than their validation RMSE, reaching a final score of 1.81. Still, their Random Forest approach was good for a third place.
The winner had to be determined by the applause meter, as the difference between two XGBoost models was only marginal (which actually surprised us this time). In the end, the group with the best score (1.18 vs. 1.19) went home with 1st place.
Although the difference in scores between first en second place was close, there was a lot more variation in the other scores than we are used to. With scores over 2.0 being frequent and even a score of 3.4 was reached (although we suspect this team to purposely overfit their model for fun).
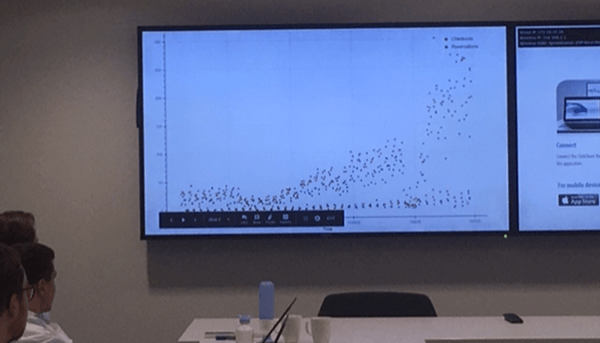
The growth of Amber visualized
When real life data isn't following the rules taught in college
We saw many of the teams struggle with the impressive (almost exponential) growth that Amber is currently going through. While at universities and in courses most of us are being taught that k-fold cross-validation is a solid approach, it is not solid in a case where you know that your training population is not representative for the labels you will have to predict. This was obviously the case in this hackathon with the goal to predict the two weeks that came after the period of training data. We explicitly mentioned the growth. Therefore, the validation approach you pick is of high importance. Actually, it was the key to winning this hackathon. Using regular cross-validation indeed did not pay off. While stratified cross-validation performed better (the winners claimed that the latter at least considers the large number of zeros in the checkouts during the night) it is not yet the optimal validation approach. Do you think you can find the optimal validation approach? Or do just want to try to create a better model? You can download the challenge below.
Want to join next time? Sign up for our upcoming hackathon.





