
Amber (now MyWheels) is an electrical car sharing company, focusing on business users. In 2020, they offered almost 200 cars at more than 50 hubs in the Netherlands. Amber worked together with Itility to create a prediction model.
Not having enough cars available at a hub to meet demand will mean Amber will be missing revenue (and even paying extra by providing a taxi), but more importantly it will mean disappointed customers. On the other hand, having too many cars at a hub means they are not driving around and will cost money instead of earning it. Because of this, it’s very important to make accurate predictions of demand-per-hub for every shift, to be able to distribute the cars among hubs in the most optimal way.
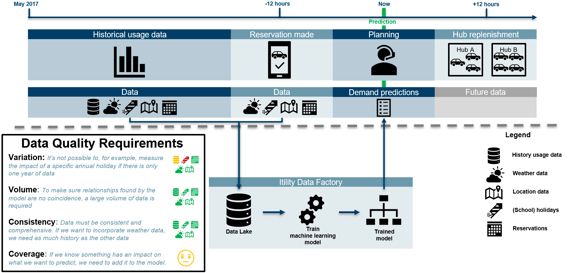
We’ve created a decision-tree based model that takes into account data from many internal and public sources, such as historical Amber usage data, weather forecasts, traffic information, etc.
The model runs every six hours and results are emailed to the operators at Amber, providing them with a forecast for each hub at the moment they are starting to plan the next shift.
The first model posed a data variation challenge. Due to the explosive growth of Amber, historical data is one of the most important data sources to make future predictions. Amber however is growing so fast that historic data becomes invalid within weeks, making it complex for the model to learn long-term patterns.
In addition, the use case is a typical example of ‘greedy data coverage’. There are that many factors that move a customer to decide to take an Amber (for example: a large meeting at another office location, an interesting conference, train strikes, own car low on fuel), that adding many data sources to the model is simply requisite to make it more accurate. However, the cost of that might be higher than the gain. So careful designing is required.
Would you like to learn what Applied Analytics can mean for you? Read more.





