Data Science. It is still a mystery box of which the contents are relatively unknown to most people. You might understand on a global level what a Data Scientist does. If you say something similar to; “Data Scientists collect data, analyze it, create some sort of model to gain hidden value, and they try to visualize the obtained results in such a way they can easily explain them to others”, you are already quite well informed about the activities of these infamous people. But is it possible to truly understand them, to see into their brain and follow some of the complex decision making that is a part of their jobs? Or even better, do you, just for a moment, want to be a Data Scientist yourself?
 If the answer is yes, this is your lucky day. In fact, not only today, because every day you have lived so far, and every day you will live in the future, you are a highly qualified Data Scientist yourself! You make data driven decisions faster than a Tesla Roadster can drive. Your brain is so much more powerful than most of the algorithms that have been created by mankind, because those mostly try to replicate what the human brain can already do!
If the answer is yes, this is your lucky day. In fact, not only today, because every day you have lived so far, and every day you will live in the future, you are a highly qualified Data Scientist yourself! You make data driven decisions faster than a Tesla Roadster can drive. Your brain is so much more powerful than most of the algorithms that have been created by mankind, because those mostly try to replicate what the human brain can already do!
Even though some Data Scientist might throw around some fancy words that may dazzle you, never forget that you have access to the most powerful algorithms yourself, which you are tapping into every day of your life. Are you curious to find out how you use some of the most fantastic algorithms, and how Data Scientists try to learn from your brain to solve problems? Then keep on reading, as I will explain this to you with the help of 3 examples that you have undoubtably a lot of experience with.
1. What to wear? (Machine Learning + Simulation)
 07:15. Your alarm clock goes off. Of course you hit the snooze button, so 10 minutes later you jump out of bed to take a hot shower. When you are done, you go to your wardrobe and choose some clothes to wear… But wait a minute… Choosing clothes might be a very complicated decision, especially for some women, yet your brain is able to perform this task relatively fast. And despite your best intentions, you could have a bad day if you make the wrong decision. Lets look at this from a Data Science perspective, so we can see whether this process can be imitated and possibly improved.
07:15. Your alarm clock goes off. Of course you hit the snooze button, so 10 minutes later you jump out of bed to take a hot shower. When you are done, you go to your wardrobe and choose some clothes to wear… But wait a minute… Choosing clothes might be a very complicated decision, especially for some women, yet your brain is able to perform this task relatively fast. And despite your best intentions, you could have a bad day if you make the wrong decision. Lets look at this from a Data Science perspective, so we can see whether this process can be imitated and possibly improved.
Choosing an outfit you are eventually happy with depends on multiple components. An important one might be if you wore the outfit recently, as it is convenient for most of us to replicate (parts) of our outfit without having to wash or iron again... However, wearing an outfit too many days is gross, and decreases your (and everybody else’s) happiness. Then there are also some special rules which are absolute no-go’s (like wearing socks in sandals, or wearing dark brown and bright purple together). A major indicator might be the activity we plan to do that day (work, sports), but also the weather is likely to have a big impact. But how do we utilize this information to choose the clothes for today that you are most satisfied with?
We create a historical table with the points discussed above. Every row is a new day (and therefore a new observation), and every column is a factor that might be of importance regarding the choice you make. This will look as follows:
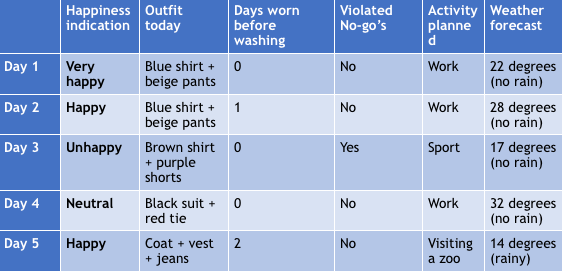
Now we only have 5 days with observations. But lets imagine we have observations of every day in your life. By using a technique called Machine Learning, we can predict your happiness based on the other columns. This is done by observing results from the past, where we detect the ‘hidden’ rules between combinations of the columns. From above table, it seems likely that you are happy if you wear a “Blue shirt + beige pants” on a non-rainy workday. So if such a day occurs again, it would be recommended to try this outfit again. Over time, your brain has developed the ability to make this decision within a split second as well.
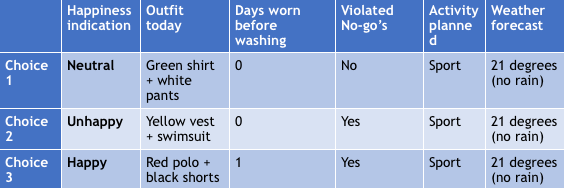
Another technique which mimics the brain is Simulation. Suppose we have the choice between the outfits “Green shirt + white pants”, “Yellow vest + swimsuit”, “Red polo + black shorts”. We need to decide which one to wear on the next day. We can think about this and picturing ourselves wearing those outfits or we test what our previously made machine learning model predicts as “Happiness indication” if we fill in the other columns. After the model makes some happiness prediction, we are able to choose the best outfit, which in this case will be the “Red polo + black shorts”.
Using these techniques we can find the best outfit for the coming day. But in practice, similar techniques are performed on high speed inside your head, and the effort of running this model every day you wake up decreases your happiness much more than the occasional bad judgement of clothes. However, in businesses, where there are large costs when a bad judgement call is made, using these techniques may actually be a huge benefit. For example, “dressing” a machine, which boils down to determining whether to disable, enable, scale up or scale down, is a similar “what to wear” problem, but in businesses the benefits are probably much larger than the costs.
2. Grocery shopping (Pattern mining + Mathematical Programming)
You are relaxing at home on your nice big sofa, and suddenly you feel hungry. You manage to pull yourself up and stumble to your refrigerator to grab a bite. Unfortunately, it is completely empty, so you go to the store to buy some of your favorite food. But what are you going to buy? Your brain solves this question by performing an algorithm that is known in the Data Science world as Pattern Mining.
yourself up and stumble to your refrigerator to grab a bite. Unfortunately, it is completely empty, so you go to the store to buy some of your favorite food. But what are you going to buy? Your brain solves this question by performing an algorithm that is known in the Data Science world as Pattern Mining.
Suppose you like buying common products like cheese, ham or marmalade. It is very likely, that you are also buying bread, since you (together with many others) know they taste well together. And people that buy bread, are also buying milk most of the time, because most people in the Netherlands are raised that way and think those products fit well together. Everybody has these connections between products in their head, like eggs and bacon, pasta and tomato sauce, etc., but what if we could retrieve all (hidden) connections from everyone’s brain…
Supermarkets are very happy to access this information, so they can increase their profits. For example, if they put a huge discount of 50% on ham, they not only get rid of the extra stock (preventing to be left with rotten food and reducing inventory costs), it is also likely that more bread and milk will be bought, so they can slightly increase the prices on those products to make more money. They figure out which groceries most people buy together by keeping records of the receipts of their customers. A table is created where you see a sample of this information.
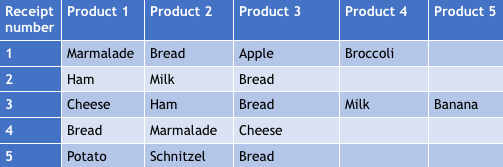
As you can see, if ham/marmalade/cheese is bought, people will always buy bread. Apparently, milk is always bought together with ham. So, we can deduce that if we increase the demand for ham, the demand for bread and milk will very likely go up as well. Finding relations in a constructive and data driven way can result in some valuable hidden gems in almost any branch. Using a smart algorithm that detects all probabilities and power of the relations, these gems can be discovered.
Once you have created your shopping list with products that taste well together, you are ready to enter the supermarket. But now the next question rises: “What path should I walk to pick up the products I need as efficient as possible?”. Your brain comes up with a route that is likely near-optimal, but you cannot be sure it is truly optimal, especially if you are buying a lot of different products in a large store. That is where Mathematical Programming comes in handy, and the algorithm that fits this problem is very well known by mathematicians and is called the “Travelling Salesman Problem” (TSP). This is because the first use case was a newspaper boy that had to find the shortest route to deliver newspapers in the mailbox of multiple houses in his area, and then return to the depot.
The optimal solution of this TSP problem requires you to construct some mathematical formula’s (y = x1 + x2, etc..) that once solved, tell you in which order you have to pick up your products, so you can minimize your travel time. The only thing you need is data about precedence of your products (example: Ice-cream must be bought last) and the distance between each pair of products (example: distance between cheese and bread is 5 meters). Of course, it takes longer to calculate this solution than immediately start walking and taking a nearoptimal route. But if we think about large transporting companies or assembly lines in factories, applying this algorithm can save thousands or even millions of euros.
can minimize your travel time. The only thing you need is data about precedence of your products (example: Ice-cream must be bought last) and the distance between each pair of products (example: distance between cheese and bread is 5 meters). Of course, it takes longer to calculate this solution than immediately start walking and taking a nearoptimal route. But if we think about large transporting companies or assembly lines in factories, applying this algorithm can save thousands or even millions of euros.
3. A night in the club (Speech Recognition + Statistical Theory)
It is finally weekend! You ask some of your friends if they want to go clubbing tonight, and of course they will not refuse, because they like to hang out with such a big party animal like yourself. You meet up with your friends and have a few beers, until you decide to relocate to your favorite club, so you can drink some more beers. Unfortunately, it is so noisy there, that you can only understand half of what your friends are saying. Despite this discomfort, everyone is having the time of their lives, so you decide to stay there and let your brain handle the Speech Recognition algorithm in the conversations with your friends.
You handle this because you hear part of a sentence and start to auto-complete it yourself. Suppose you hear: “Hey, … I get another … for you?”. You will fill in the blanks and make an  educated guess that you were asked whether you need a refill, so you reply with a nodding gesture and point to your empty glass. But now we want to capture this trick of your brain with actual data. Speech can be represented as sound waves with a certain frequency.
educated guess that you were asked whether you need a refill, so you reply with a nodding gesture and point to your empty glass. But now we want to capture this trick of your brain with actual data. Speech can be represented as sound waves with a certain frequency.
And although every person has a unique voice, their soundwaves are quite similar. If we collect enough of these sound samples and the words or sentences they represent, we can predict what someone says by checking which sound pattern is most similar to the pattern this person produces. Even if there are words missing from a sentence, which results in missing data, the algorithm is still able to find a the most probable message. This technique can be used to learn robots or voice assistants to respond to human commands, which is of course extremely cool while also valuable for the world if correctly applied, as we can reduce a lot of wasteful activities!
After you chatted a bit with your friends, you spot a beautiful (wo)man. You are wondering if this person might be the love of your life, as this person is a god(dess) compared to everyone else you ever met. It might be interesting for you what Statistical Theory can tell us about what strategy to follow in order to obtain the highest probability of ending up with the perfect partner for you.
To analyze this problem, lets use the following assumptions. Over time you will encounter 100 possible partners, one at a time. You are allowed to either choose the current candidate, because he/she will surely love you back if chosen, or you reject the candidate and wait for the next possible partner to appear in your life. However, once you choose someone, the ‘game’ ends and you cannot choose another. And when you reject someone, you can never come back to them because they will not love you back anymore. You can compare each candidate against all previously rejected partners with perfect accuracy, but you do not know when you encounter “The one”. The question is, what is your rejection strategy to have the highest probability of ending up with your perfect match?
partner to appear in your life. However, once you choose someone, the ‘game’ ends and you cannot choose another. And when you reject someone, you can never come back to them because they will not love you back anymore. You can compare each candidate against all previously rejected partners with perfect accuracy, but you do not know when you encounter “The one”. The question is, what is your rejection strategy to have the highest probability of ending up with your perfect match?
The answer is as follows: You should first do some market research and reject all of the potential partners you encounter, up until a certain point. Now that you have a solid baseline where you can compare your future partners to, you should accept the first partner that is better than all of your previously rejected partners. But at which point should you stop the market research phase and start accepting the best partner found so far?
After some mathematical calculations we can conclude that this optimal point is reached at 1/e. (e is a mathematical constant of importance, just like pi: π ). This boils down to ~ 1 / 2.718 is about 37% of observations. So after you have rejected 36 potential partners, you should accept the first partner that is better than all previous ones and in this way you have the highest probability of finding the ultimate prize. So the advice is to determine for yourself if you are still in the ‘market research’ phase and should not yet commit yourself to someone, or are already beyond that point in which case you have to pursue this god(dess) in the club. However, some things should not be solved by applying Data Science, as the real answers to the subject of love lie within the heart, not the brain!
Conclusions
I hope you enjoyed this article as much as I did writing it, and that you have learned how Data Science techniques can be used to solve everyday problems. Next time you are dressing yourself, going the supermarket, or seeing an attractive (wo)man, you might want to think about how Data Science can help you make the correct decisions in life!
Also, I wanted to show you that Data Scientists just replicate the logic that is also found in the human brain. They use this brainpower that all of us possess in order to create models that a computer is able to quickly solve. This is especially useful when the problems get so large that they scale up to be highly complex puzzles that we as humans are unable to solve within a reasonable amount of time.
Lastly, since we established that every person is a Data Scientist themselves, I want to encourage you to think about any possible cases where you would like to see me develop an algorithm for. It can be a business case, another everyday life example, or anything else that comes to mind, but please post a comment below this article with your thoughts!