

When developing and running any application, it is important that end users have a positive experience using it. In the DevOps way of working, you continuously balance between stable product performance (that end users are happy with) and product innovation (releasing new product features and improvements). As a product grows more mature and gains a larger user base, the focus on stable performance increases. One way to enhance this stable performance is through Site Reliability Engineering (SRE). In SRE, software engineers take on the role of system administrators. Using their ‘software goggles’ they introduce smart monitoring and automation to improve quality, reduce waste, and increase overall efficiency. In this blog, we zoom in on how SRE translates end-user experience into quantifiable metrics.
This is a move away from the traditional Service Level Agreement (SLA) approach, toward a way of working where the focus is on the needs and experiences of the end user. An SLA is often defined from a fragmented technical perspective: what performance can we deliver on the various technical components versus reasonable costs? End users, however, do not care about the technical specs – they just want their application to work. Take, for example, the following situation. An end user complains that their email is not working. A typical SLA would guarantee a server uptime of 99,9%, so you investigate the source of the complaint. As it turns out, the server is still up and running, but the connection to the database was lost. This means that you are compliant with the defined SLA, but your end user is still unhappy. This mismatch is one of the things SRE aims to solve.
Living up to your end users' expectations
Working from an SRE point of view, our focus at Itility is continuously on the end user and his experience. We begin with defining Service Level Objectives (SLO) together with key users. This is the part where end users will share their expectations about the application. Holding on to the email example, requirements could be: I want my email to always be available, it should respond with fast loading times, I want it to be reliable without errors, and I want to see the correct content. Initially, these objectives can be fairly general and highly subjective. What does the end user perceive as always available, or how long should opening the application take for the user to perceive it as fast?
That is why the next step is important: translating the SLO sets defined by the key user(s) into SLIs (Service Level Indicators). These SLIs are metrics we measure on a component level, for those components used to deliver functionality to the end user. They offer guidelines for improving and finetuning those components to realize the SLO. In-depth knowledge of the software application is required for this part. The technical application expert needs to draw up the landscape architecture, allowing us to find the relevant components to measure via appropriate SLIs. For the email example, this results in SLIs that do not only cover server uptime, but database availability as well.
Measure your performance
After the Service Level Objectives and Indicators are defined, we start monitoring the application to see if we meet those requirements. Next step is to act upon the results. That is why we have created a dashboard with all SLIs, providing us with a clear overview of the application’s performance. For good comparison, all measuring units are translated to a value between 0 and 100% (of course there is an additional tab with the ‘original’ measuring unit like seconds, numbers, or percentage). Red items are falling short on the requirements, but the green ones are meeting the targets.
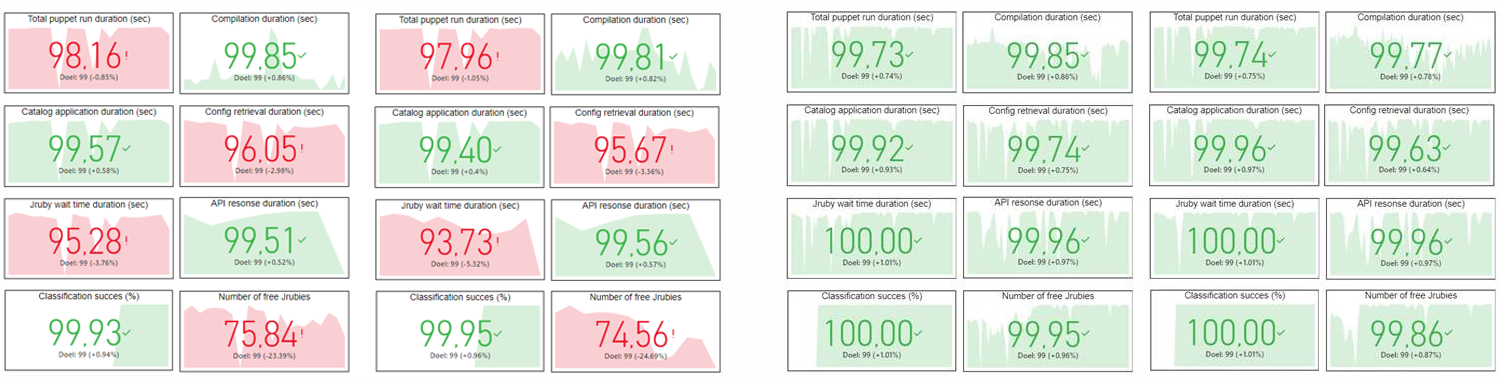
Left: Report of SLI performances IMIP application – first run. Right: Report of SLI Performances IMIP application – current status
Do not fix what is not broken
Although it might seem counterintuitive, the first step when something seems to be broken on the SLI dashboard is not to repair it. First, it is important to evaluate the end user’s experience. We do this via monthly review meetings, in which our end users are asked to explain their perception on the application’s performance.
For example, our Itility Cloud Control platform team is responsible for managing an application called IMIP. We agreed with our end users that the application should be ‘always available’ and ‘fast enough’, so we had our SLOs. Translating “fast enough” to SLIs, we initially agreed with our end users that IMIP job durations should be completed within 120 seconds. Later, we discovered that the job runs took 180 seconds to complete instead, so we did not meet our SLIs.
Instead of immediately refactoring the IMIP application, we first called our end users to an evaluation meeting in which we discussed their experience with its performance. They explained that they were satisfied with the stability of IMIP and speed at which it completed its jobs. So, it turned out that we had set our indicator goal too tight. The end user perceived this waiting time as acceptable, so we did not have to put effort into improving the run time. We simply adjusted the SLI instead. As a result, we were able to spend time on other features that were important to our end users.
Finding the balance between Dev and Ops
This example illustrates the continuous process of finding a balance between measuring, spending time on repairing (operations) and spending time on improvements and new features (development). Sometimes lowering a goal results in a more satisfied end user because the DevOps team can then spend its time on more important matters.
The essence of SRE is continuous improvement, which is inherently an ongoing process. This means we should not dwell on the startup phase because we think we might miss something, but rather just get on with it. Decide on a starting point and start measuring. If your SLI dashboard shows only green values (you met all the required SLIs), but your end users are unhappy, the solution is clear: evaluate and adjust.
It is important to keep reviewing the results together with your end user and to start finetuning your SLIs. Which indicators should be measured that are not in place at this moment? Did we miss our targets for any of the indicators? How can we fix our performance? Do we need to fix our performance? This is an interactive process where you continuously look for the balance between spending time on application stability and the introduction of new features. The ultimate goal: to provide end users with a positive experience when using the application.
Want to know more? Read this elaborate explanation about SRE and how it relates to DevOps.





