Training young minds is one of the Itility’s core values. So, in addition to running a Young Professional Program, we engage in a number of activities to allow students and young graduates to learn more about data science. So recently we co-lectured with dr. Anna Wilbik at the Faculty of Industrial Engineering and Innovation Sciences, TU Eindhoven.

Prof. Wilbik teaches a master’s course in business information systems management and explains in the series of lectures how developments in technology can serve businesses – which includes an introduction to neural networks, their principles, and practical uses.
As one of Itility’s data scientists, I joined prof. Wilbik’s lecture on neural networks to showcase some of the projects we carried out at Itility that employ deep learning.
Prof. Wilbik already introduced the concept behind a shallow neural network, so I could build on this knowledge and easily explain the principles that are at the basis of a deep neural network architecture.
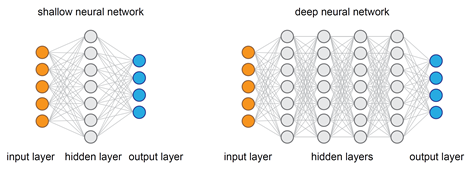
To briefly summarize it here: in the shallow neural network data introduced to the network goes through a single round (hidden layer) of pattern recognition. In contrast, deep neural networks consist of several hidden layers, which can be of a different type, so data goes through multiple pattern recognition processes. I specifically mentioned convolution and pooling layers, two common processes used in the networks for image recognition.
This gave me a chance to smoothly talk towards the first of his practical examples and one of the ongoing projects at Itility.
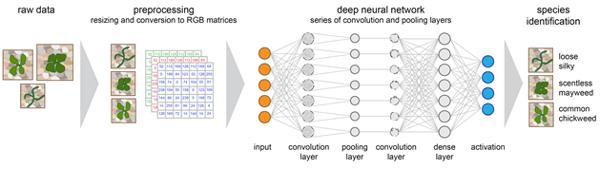
Project example 1: predicting the quality of tomato seedlings - example of a deep neural network for image recognition
If you follow our blog, you might have already read about this project, as our previous hackathon was organized around it. Briefly, this project started as collaboration with Wageningen University to develop an automation system for scoring quality of the seedlings (which can be interpolated to the seeds quality).
Our first step here was to look through the already existing network architectures and select the one that would serve our needs best. This practical tip can significantly decrease the time needed to develop the right solution as it’s easier to tweak the existing architectures rather than build from scratch.
While indeed this can be a huge time saver, you should be prepared that you will go through a period of trial and error along the way. I illustrated this with an example of using Google’s Inception network for “Seedlings Quality” project. At the first glance it seemed tempting to use this network, though fairly complex, but trained on a large dataset. However, it requires longer periods of re-training and is unable to converge or it overfits.
The solution we have chosen in the end consisted of several convolution- and pooling-layers and is based on the VGG16 (Visual Geometry Group of the University of Oxford) network.
Project example 2: detecting anomalies in server metrics
 In this project we are feeding a neural network with metrics data collected from a large number of IT servers. The long/short term memory network that we used compares the predicted values to the actual ones, recognizes any anomalies that appear in the data and highlights them. Those results are then passed on to an IT stack engineer who maintains the servers.
In this project we are feeding a neural network with metrics data collected from a large number of IT servers. The long/short term memory network that we used compares the predicted values to the actual ones, recognizes any anomalies that appear in the data and highlights them. Those results are then passed on to an IT stack engineer who maintains the servers.
At this point students became interested if (based on this data) it is also possible to predict a malfunction of the server. I explained that the nature of the anomaly is that it occurs infrequently and is not always based on the same pattern. Therefore, the model would first have to be taught which patterns are associated with anomalies. That would require tagging the “normal” versus “abnormal” patterns; which would have to be done by a trained specialist – for multiple servers a truly tedious task.
Project example 3: predicting prices based on a product description
Final example was related to the internet sales at eBay or Marktplaats. It turns out that buyers tend to offer higher prices for the items on sale if the description of the product contains certain keywords. At Itility we strive to identify those patterns and therefore optimize descriptions to reach best sales values. For this project we used a recurrent neural network - a common solution for reading texts.
February 2019 data scientists Kevin Schaul and Lars van Geet held another lecture on data science in the real world.