

An important factor when implementing a digital solution is to use the right tool for the job. One of the cloud toolsets is offered by Google Cloud – so we organized a deep dive to get familiar with Google Cloud Platform (GCP) services. With a team of three cloud engineers and two data scientists, we ran a series of trial projects to get a good understanding of the platform's foundation and data services. Here is a summary of our findings.
Foundation
The process of building an enterprise-level cloud foundation is not straightforward. The first step is knowing the structure of your cloud environment. GCP uses three types of entities to structure your cloud. First is the organization – this is the highest level in the hierarchy – and can represent your company. Next are folders, which refer to departments and their respective teams. And last, there are projects. Projects refer to an application stage and contain all cloud resources that make up your solution.
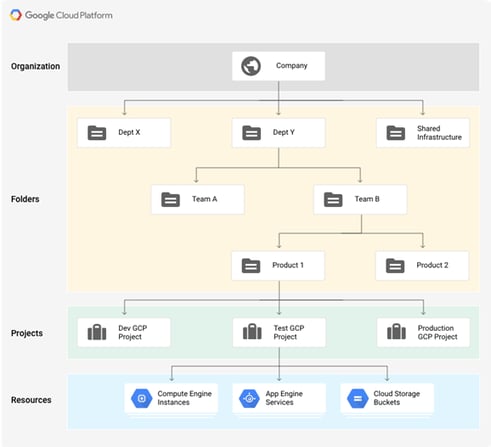
Hierarchy overview in GCP
Great! Now we have a structure to organize our cloud. But how do we implement our solutions?
Infra-as-Code
Google’s Deployment Manager is the go-to PaaS component for provisioning. It enables the declaration of what we want to have running in our projects. These declarations act as a ‘source of truth,’ meaning if we remove or add a resource to the declarations, Deployment Manager will automatically make that change happen. It is very similar to Azure Resource Manager (ARM) and AWS CloudFormation in this regard. Compared to these two, Deployment Manager executes much faster and is easier to work with. ARM has some built-in logical functions that you can use in your deployments. With Deployment Manager, however, you can use Python code directly to create your declarations. This enables you to build more complex situations than with either ARM or CloudFormation.
By putting our declarations in Git repositories and using CI/CD, we now have a powerful way of automating and controlling our cloud, while also keeping track of different versions. We can easily roll back, (dis)approve, and monitor changes we make in our cloud environment. In GCP, we can use Cloud Build to execute our build pipelines and create triggers to specify when we want our build to execute.
But what provisions are we going to use in our cloud?
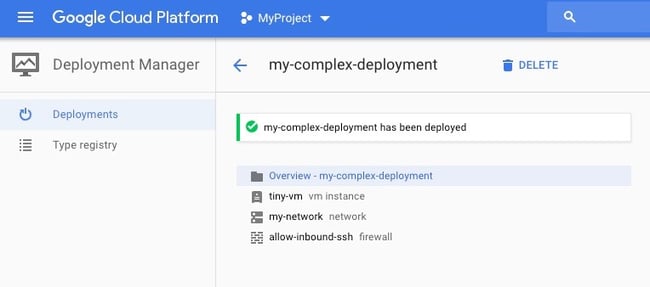
Deployment Manager
Networking and compute services
For our foundation, we looked at basic networking and compute services. For networking, we created a Virtual Private Cloud (VPC). This is an isolated network from which you can attach resources that need an internal IP address. A VPC in Google Cloud is global by nature, meaning that machines from Europe can reach machines in Asia or the US with near-zero configuration. This is a big difference compared to Azure, where you would have to go through multiple steps to set this up. Within our VPC, we created several subnetworks, which are tied to regions.
As for compute services, there is a wide variety available with different pricing models. Most interesting here is the Kubernetes offering. Google Kubernetes Engine offers two modes of operation: Autopilot and Standard.
Autopilot enables you to manage your applications and clusters, while Google Cloud takes abstract master nodes and node pools away from you and manages them for you. This allows you to easily create high-available services while taking away some of the headaches you encounter when hosting your own Kubernetes. Standard mode offers direct control over the underlying compute resources for more flexibility.
It’s very #cool that we can easily perform automation with Deployment Manager to set up networking and compute resources. Now, we must find a way to monitor these resources.
Monitoring and alerting
Cloud Monitoring is the native service used for monitoring your GCP environment. This service visualizes your infrastructure metrics and logs and alerts you when something significant happens. What really sets Cloud Monitoring apart from its competition is the built-in incident manager to manage these alerts. Using Deployment Manager, we can automate the rules for when to alert. For example, we implemented a rule in Cloud Monitoring that alerts when someone’s access rights are changed, or when our infrastructure load spiked.
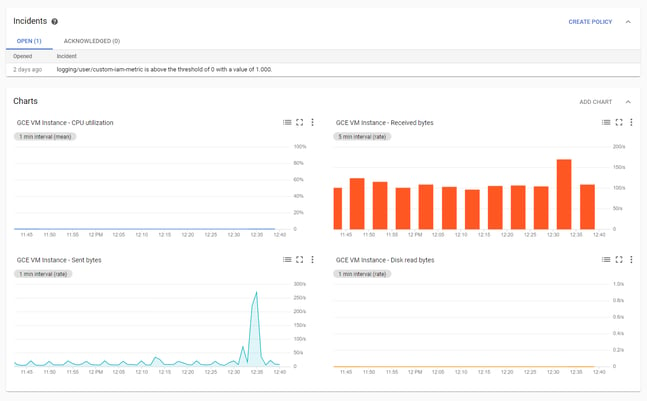
Cloud Monitoring overview
Data services
Google is well known for its data and machine learning solutions, so obviously we wanted to put those to the test. To make a clear distinction between the data services, we created three personas – the data engineer, the data scientist, and the data analyst – and explored which services are of most use to them.
The Data engineer
Data engineers work with big data and solve problems using ETL and distributed processing. For data engineers, we have found the services Dataproc, Dataflow, BigQuery, and Composer to be most useful.
Dataproc is used for migrating Spark and/or Hadoop jobs to Google Cloud. It allows you to spin up and tear down clusters, and it provides some automation to create complete workflows. Dataproc gives you a lot of control since you can choose the underlying infrastructure that runs the service. This means you can specify how big or fast you want your machines to be. The downside is that you need to specify more configurations yourself to manage this service. However, Google has recently announced a serverless mode for Spark-submit jobs. This operation mode provides auto-provisioning and auto-scaling.
Dataflow is used when creating data pipelines from scratch. It is a managed service for Apache Beam, which lets you define batch and streaming ETL pipelines. It is especially interesting for streaming/real-time use cases. Google provides a collection of templates that are ready to be used, or you can write your own job with the Python or Java SDK. Dataflow then manages the horizontal and/or vertical scaling of underlying resources.
BigQuery is the serverless data warehousing service with an SQL-like interface. It was pretty easy for us to integrate this with our DataProc clusters. It offers cheap storage and now, it also allows loading Hive-partitioned data. BigQuery is a good option to store data that should be easy to query for ad-hoc analysis, dashboards, ETL, or ELT.
And lastly, Composer is the managed Apache Airflow service for data pipeline orchestration and scheduling using Directed Acyclic Graphs. If you already decided to use Airflow in some way, then we recommend using Composer, since it takes away some of the pain of setting up and maintaining the environment. If you need data pipeline orchestration, it is a good option as well. However, it is important to keep an eye on costs since resources will be running continuously.
If you are used to writing code in Databricks, you’ll be pleased to find that it is available in GCP and integrated with GCP products, such as GKE and BigQuery. Additionally, Google has announced a similar offering: Vertex AI Managed Notebooks. These are Jupyter notebooks, for which you can easily select Python, PySpark, or R kernels, resize hardware from within the notebook, and schedule notebook execution.
Data scientist
Data scientists work with machine learning (ML) solutions. Vertex AI is the go-to service in that case. It gives access to all infrastructure optimized for ML computation, such as GPUs, hosted Jupyter notebooks, and deep learning machine images. Vertex AI is made to cover the entire machine learning process from development to deployment and to enable ML operations (MLOps)
Vertex AI offers the following useful features (among others):
- Labeling service – create data labeling tasks for either people hired by Google or your own domain experts
- Workbench – a notebook environment where you can create your own notebook server with the necessary specs
- Feature Store – a service that is useful when you have a real-time model deployed and needs to consume feature data with low latency
- Vertex AI Pipelines – a managed service for Kubeflow Pipelines, which allows you to create ML workflows as DAGs
- Endpoints – deploy models to serving infrastructure, where they can be embedded in applications
- Model Monitoring – continuously monitor for data drift or training/serving skew
Note that not all of these functions may be necessary for your use case. If you have a real-time recommendation system, Vertex AI seems more relevant than if you are running a batch scoring pipeline.
Data analyst
Data analysts are using business intelligence and data visualization. Google Cloud offers two tools, DataPrep and DataStudio, that are great for this.
DataPrep is a data pre-processing no-code tool, which allows you to perform simple data cleanup and computation to prepare your data for the next step in the process. It also shows the analyst information about the data that is coming in, such as the distribution of values per column or the number of missing values. This information can then be used to click together automation to get your data ready for the end-user. DataPrep is a nice tool in terms of its functionality, but it is provided by Trifacta, a third party on GCP. This means that if you want to have more functionality around deployment and automation, you’ll likely need to use tools from the Trifacta ecosystem, rather than open source or GCP tools.
DataStudio is a data visualization tool that you can use to build rich, interactive dashboards and reports, making it very comparable to a service such as PowerBI. A great feature of DataStudio is that it has good out-of-the-box integrations with Google’s other data services such as BigQuery and DataPrep, making it much easier to work across disciplines. Also, if you run DataStudio with data inside BigQuery, you will only pay for the queries that BigQuery executes, not for DataStudio. If you are planning to use it as a standalone service, evaluate what kind of integrations are important for your use case before deciding.
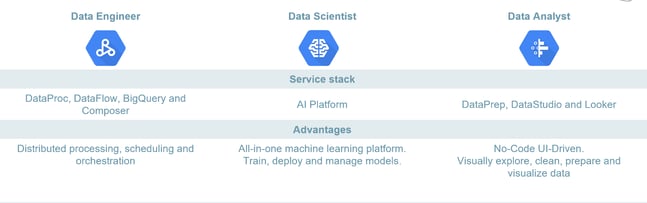
Data use cases
GCP: the verdict
It’s clear Google is on a mission to be the number one. Google Cloud has a vast selection of services for different use cases. Spinning up and tearing down resources takes seconds rather than minutes. But GCP is also newer to the game, and we see that as well.
When artificial intelligence and machine learning play a crucial part in your business, you cannot go wrong adopting Google Cloud in your stack, especially given the strong community surrounding it. A benefit is also the connection of GCP products to open source software. The various serverless tools help develop scalable applications and reduce ops.





