Previous hackathons covered image recognition and time series data, it was therefore only appropriate that this time to bring something new to the table, so we decided to challenge our participants with classification of the audio files.
Machine learning for audio files is a growing field, with newest developments implemented in applications using speech recognition, home automation, and surveillance, among others. While daily life solutions need to be able of extracting the important information such as a crying baby or breaking glass from all the background “noise”, the task for our hackathon had to be simplified to allow participants reaching a solution within one evening.
We selected a public data set (available on kaggle), which consists of over 2500 audio recordings of different sounds (e.g. applause, trumpet, saxophone, cough, squeak, fireworks, etc.). Data set was divided into training, validation and test data, with the goal to classify test samples (250 of them). One of the obstacles that participants will encounter is the uneven length of the file ranging from 1 to 30 seconds, with the sound sometimes playing only in the middle or at the end.
As for many of the participants this was an uncharted territory, so we handed some additional clues on how to approach the data.
- Explore the possibilities that existing libraries offer. Librosa and TuneR are among the most common ones used for audio processing and analysis.
- Transformation of the audio file. Audio files can be looked at as a time series and plotted as a frequency over time, or as an image and displayed as for example a heatmap.
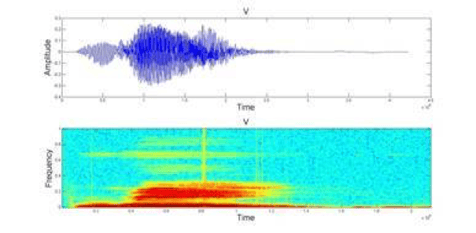
- Fast Fourier Transformation (FFT). It’s one of the common methods to transform an audio file. Alternatively, one can use a Mel frequency cepstrum (MFC), a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency.
The final piece of information: the winner will be selected based on the accuracy of the classification of the test data.

Approach: time series versus images
As none of the participants had prior experience with audio files, it meant this hackathon involved a lot of exploration and time spent understanding the data itself.
The room was split roughly in half on whether to use a time series or an image approach. Nonetheless, almost everyone used a combination of Fast Fourier transformation combined with MFC and looked for unique features in the data to classify the samples.
File preparation: cutting versus expanding
As mentioned above, files provided varied in length. Therefore teams had to devise a strategy to even them up. While most chose to simply trim their files to one second, with the caveat of losing some relevant data in the process, one team came up with a solution where they select only the loudest one second of the recording. Another team decided to expand the files by adding the “empty” recording to make all the files last 30sec. This approach however posed a problem of sufficient computing power, which would not be possible without access to an external server.

Learning: decision trees versus convolution
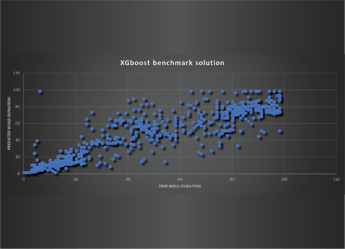
Unfortunately, most of the teams where held back by the initial problems of data processing and were left with little time for developing the right model to provide the final solution. Teams that managed to get to that stage used either a one-dimensional decision tree (specifically an XGBoost model) for time series, or a convolutional neuronal network (CNN based on Keras library with TensorFlow) for image data. Both of those teams managed to score high on the classification of the test data, with XGBoost’s team achieving 65% accuracy and CNN 76%.
Want to join next time? Sign up for our upcoming hackathon.