
IT applications generate numerous log messages on a daily basis. Within Itility we are responsible of managing such applications that generate thousands of logs on a daily basis.
In general, the problems we were facing, focused on:
- Loss of focus due to the volume of thousands of log messages
- Wasting resources by investigating pseudo-events: applications identify certain logs as 'severe' that in fact are not (false positives); each of them take time to investigate
- Missing true incidents: applications identify certain logs as 'low impact' that in fact are not (false negatives).
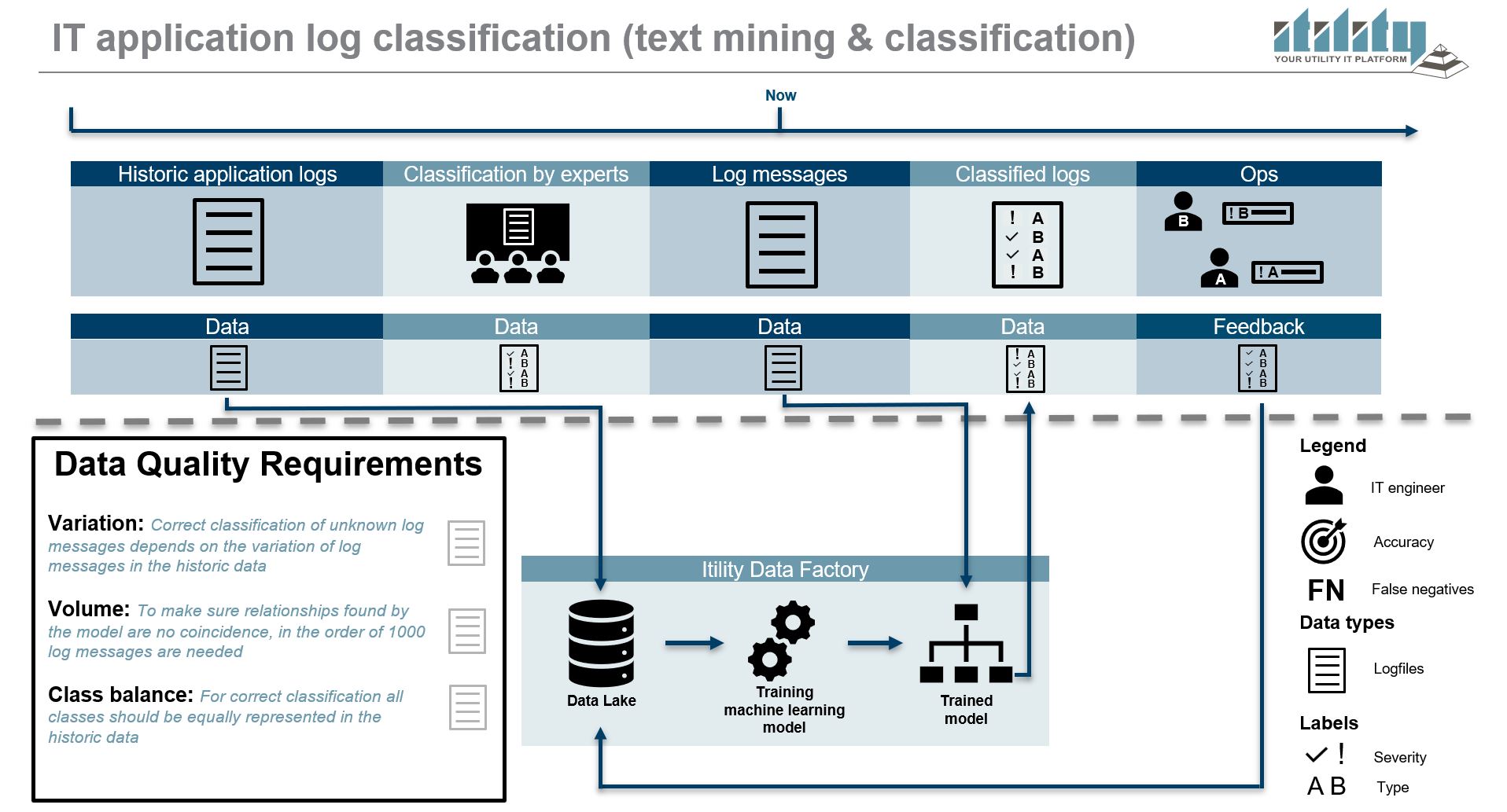
To prevent the above, we created the 'Log classifier'.
Using text mining techniques, model assembling and a trained algorithm on textual data, a Document Term Matrix (DTM) is created by calculating if a word occurs a in log. This ‘dictionary’ classifies logs and determines severity and receiver of the alert based on the actual words / content of the event. The Log classifier uses wisdom of the crowds: it combines the opinion of multiple domain experts.
This has reduced the false positive rates with 15% and the false negative rates with 2%. More importantly, it can classify logs it has never seen before, so can interpret events that never happened before.
Classification is not perfect from the start (predicting false positives/false negatives), however the algorithm is improved by feedback by the domain experts.
Would you like to learn what Applied Analytics can mean for you? Read more.





